How machine learning helped calculate server energy consumption
Nour Rteil | Dec. 16, 2020
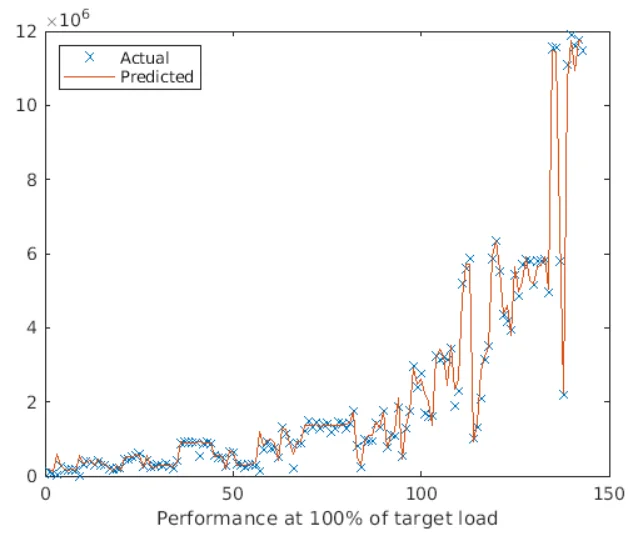
Without a doubt, machine learning has transformed data centres. It has helped immensely in increasing energy efficiency and reducing carbon footprint by autonomously adjusting cooling systems, analysing IT infrastructure to determine how to best utilise resources, and generating recommendations for optimal physical placement of IT equipment. In the past, this has required onsite software and/or hardware installation, an invasive intervention to monitor utilisation and temperatures. However, INTERACT shows that machine learning can be used as an alternative to this. Pairing the energy model described in [1], with the correct algorithms has enabled us to estimate the energy consumption of servers based merely on their hardware configuration. It results in a faster, more self-contained tool that not only facilitates the calculation of CO2 emissions but also forecasts costs associated with operating the servers. So, how did we bring this about?
Data capture
The machine learning model was fed by hundreds of filtered server records published online by SPEC. A server record contains its configuration details (for example CPU specs, RAM, server’s release year, etc..) and the results of the SPECpower_ssj2008 benchmark (for example idle power, power at full load, and performance score).
Smart modelling
The model was trained to predict the idle power, power at full load, and performance at full capacity for any server configuration using a 3-layer neural network model that takes in these input parameters: CPU cores, CPU threads, CPU frequency, RAM capacity, and server’s release year. The nature of constructing a neural network algorithm that ties in the input parameters with the output parameters is very complex. However, a series of models were examined, each using a different combination of input parameters, and we stuck with the combination that generated the highest accuracy levels. The results are then plugged into the energy algorithm, along with other parameters (like server utilization and PUE), to generate the annual energy consumption and workload of that specific server model. The use case has been further extended by running the algorithm over thousands of pre-configured models with their prices. This enabled us to recommend the best server models to refresh existing servers with, in terms of energy, CO2 footprint, and cost.
Continuous improvement
With a growing interest in energy efficiency and the carbon cost of manufacture, I am hoping more suppliers and manufacturers will be willing to share data around this with the public. This kind of information will enable accurate calculations around how much energy and materials can be saved by avoiding the need for new manufacture. Work on this is in its early phases. Openness will surely bring innovation and improvements for both suppliers and consumers alike.
[1] R. Bashroush, "A Comprehensive Reasoning Framework for Hardware Refresh in Data Centers.” IEEE Transactions on Sustainable Computing, 2018. DOI: https://doi.org/10.1109/TSUSC.2018.2795465